
Author: Ignacio Aguaded – Translation: Erika-Lucia Gonzalez-Carrion
This is not a letter soup! They are the acronyms of some of the best known scientific production indexes. Both researchers and journals are ranked by their level of productivity and impact in the scientific community, usually measured by citations that are generated in other publications.
In recent years, the H index, proposed by Jorge Hirsch of the University of California in 2005, has been very strong. Its popularity has been due to Google (as well as other large databases such as Scopus, WoS). Integrated in its star product for the University: Google Scholar.
H, as a bibliometric index, aims at simultaneously measuring the quality (based on the number of citations received) and the amount of scientific production of a researcher or magazine, always applied to that database (the index of a researcher at Google Scholar is not the same as in Scopus). This index is very useful for detecting outstanding researchers in an area of knowledge, because it crosses and evaluates the number of publications of the author and the citations obtained by these most significant publications, indicating their level of progression throughout an academic life. It is calculated by ordering the publications of a researcher by the number of citations received in descending order and then numbering and identifying the point at which the order number coincides with that of citations received by a publication. Thus an H = 5 Index would be when there are 5 publications that have received at least 5 quotations each.
The H5 is configured taking only the last 5 years of the life of a researcher or a magazine, so as to have a period that allows comparing research trajectories by eliminating the accumulated factor (a senior and a junior with 5 years of academic life would be comparable Much better with the H5 than with the absolute H) because only the publications and their appointments of the last 5 years would be computed.
Also the G index, like the H, quantifies the bibliometric productivity of an investigator. It was proposed by Leo Egghe in 2006, and is also calculated from the citations received. It is similar to the H index, but more complex in its calculation, and more discriminating, allowing to differentiate more than H. It is calculated by ordering the publications of a researcher by the number of citations received in descending order, numbering the position, and generating two new Columns: number of citations received accumulated, and position number squared. Next, the order number of the position in which the number of accumulated citations is equal to or greater than the squared number is identified. For example, an investigator has a “G” index when, considering the “G” most cited articles of that author, the number of citations accumulated by these “G” articles is greater than “G” squared. Thus an index G = 10 is the number of citations accumulated by these 10 articles most cited, greater than 10 squared.
The i index is very simple to calculate and is defined by the number of publications with more than 10 quotes from an author or a publication. It has been popularized by its use in Google Scholar. We can also talk about the i5 for those jobs with more than 10 appointments in the last 5 years.
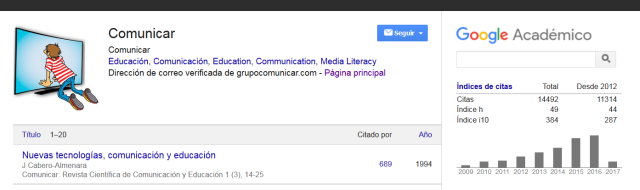
These indexes, along with many others that we talk about or will do in this School of Authors (index of immediacy, quartile, SJR, IF, SNIP, Citescore, Score RG …) are increasingly popular and reflect curricula and trajectories not only the researchers, but also the scientific journals.
Recently a publisher of “Comunicar” went to an international congress and after asking her name and nationality, they asked her for her number H. We must be prepared and … “updated”. By the way, Google creates and assigns without asking, although it is not public.